
こんにちは、うしまる(@usitubo)です。

TensorFlowを実行したらGPUのメモリがカツカツに…
PythonとTensorFlowで機械学習するとき、主にCPUを使うか、GPUを使うかが一般の人の選択肢になると思います。
GPUはこういった計算を行うのにCPUよりも優れていて、学生の頃から趣味でゲーム用に高性能GPUを積んでいる人はそのまま機械学習やAIを試すのにももってこいのPCがあるといった状況で嬉しい限りです。
そんな計算速度を向上させてくれるGPUですがそのまま使用するとどうもTensorFlowが無尽蔵にGPUのメモリを食い散らかして動作が止まってしまうという状況があります。
具体的にはこんなかんじ
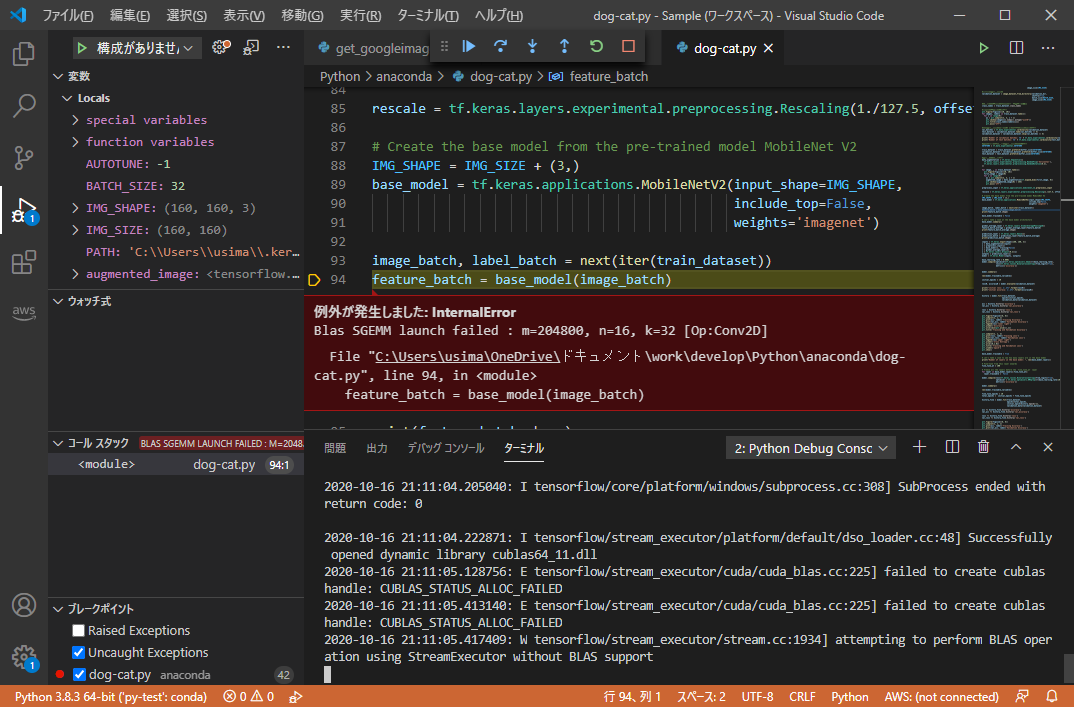
[E tensorflow/stream_executor/cuda/cuda_blas.cc:225] failed to create cublas handl handle: CUBLAS_STATUS_ALLOC_FAILED [E tensorflow/stream_executor/cuda/cuda_blas.cc:225] failed to create cublas handl handle: CUBLAS_STATUS_ALLOC_FAILED [W tensorflow/stream_executor/stream.cc:1934] attempting to perform BLAS operationation using StreamExecutor without BLAS support
TensorFlowの画像認識サンプルを動かしているとInternalErrorでプログラムが停止していまいました。具体的なエラー内容は上の方に並べてみました。先頭の”E”がError(エラー)で、”W”がWarning(警告)ですね。
原因を調べてみたところどうもこれが原因でした。
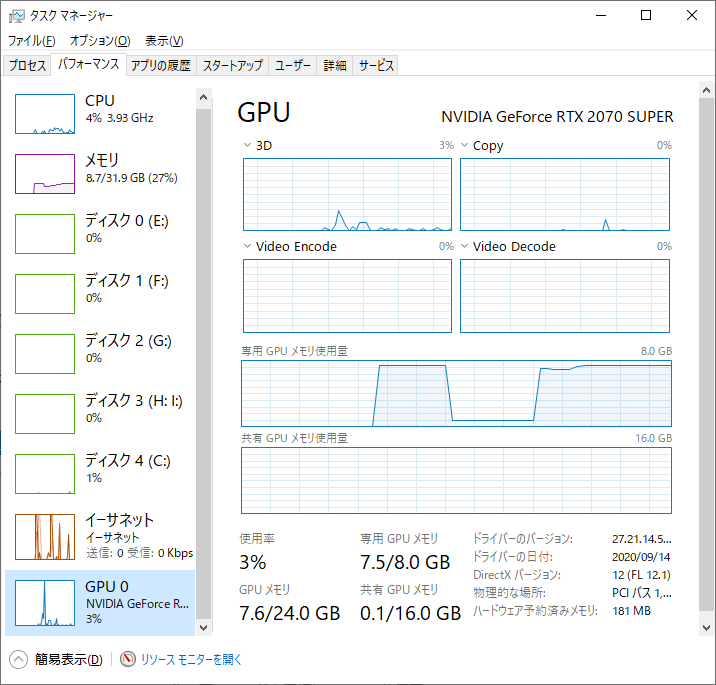
GPUのメモリがプログラムが動き始めてからほぼマックスつかっている感じです。ちなみに何もしていないときは下のような画像になります。
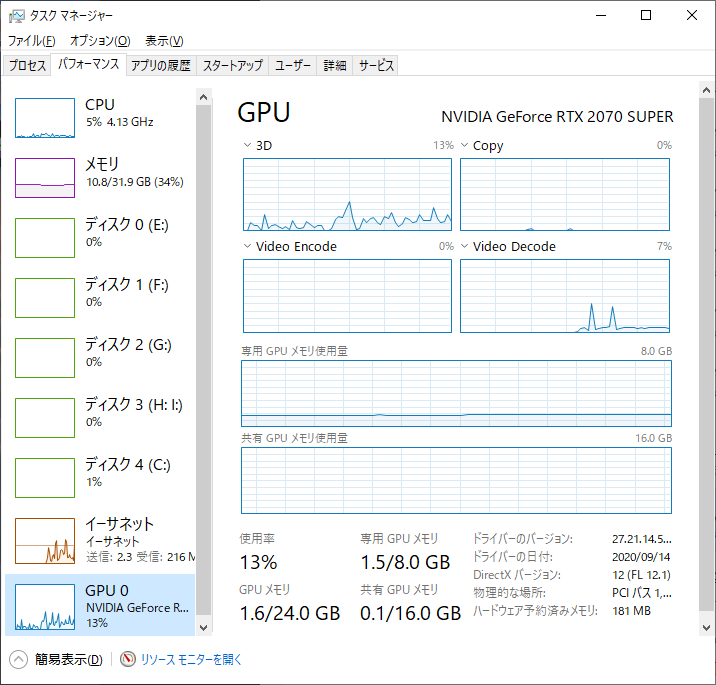
だいたい1.5GBくらいですね。少し同時に動かしているソフトもあるので起動したてとかだとほぼ0に近いときもあります。
TensorFlowをそのまま実行するとGPUのメモリがすべて食われてしまうみたい…
次の章で解決策を紹介していきます!
TensorFlowで使用するGPUのメモリ使用率を制限する
TensorFlowを動かしたときにGPUのメモリを無尽蔵に食い尽くさないようにするにはソースで対応する必要があります。
参考コードを紹介します。
import tensorflow as tf
#GPUの設定
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices) > 0:
for device in physical_devices:
tf.config.experimental.set_memory_growth(device, True)
print('{} memory growth: {}'.format(device, tf.config.experimental.get_memory_growth(device)))
else:
print("Not enough GPU hardware devices available")
こちらのコードをできるだけ実行しようとしているソースの先頭らへんで記述するようにしてください。このコードを記述して実行した結果無事に画像認識のサンプルコードを動かすことができました。
その時のGPUの使用率はこんなかんじ
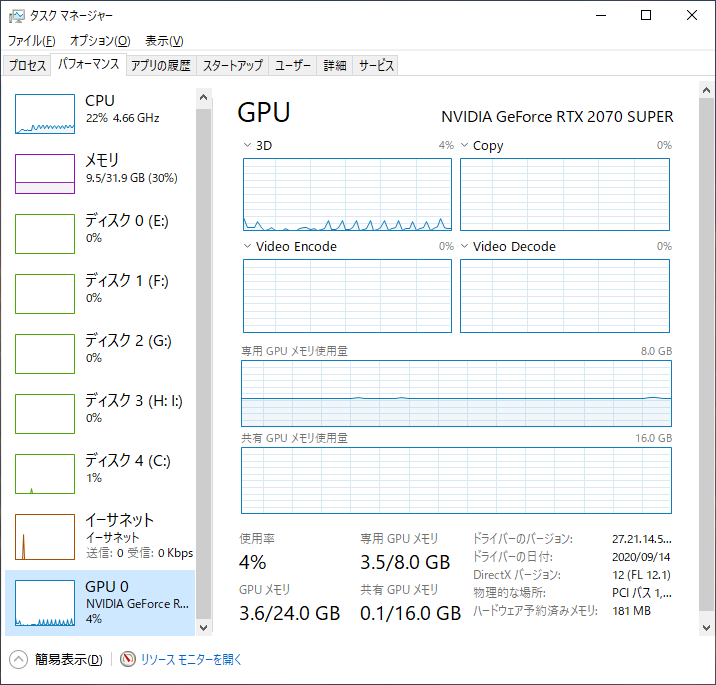
もうちょっと使ってもいいんじゃという感じはしないものの、半分くらいで安定しているのでこれで予期せぬ例外に襲われることも無いですね。
それでは今日はこのへんでノシ
ポチッとしてもらえると励みになります!














TensorFlow実行したら途中でエラーになってしまった…
もしかしたらGPUの設定がまずいかもよ?
今日はそんな記事です。