
こんにちは、うしまるです。
今日はPythonを使ってWebサイトから取得したHTMLデータの抽出をしてみましょう。こういったHTMLソースを取得してきてデータを加工したり、何かに活用したりすることをWebスクレイピングといいます。
Webスクレイピングとは?
Webスクレイピングという言葉を知っていますか?
Webスクレイピングとは、Webページから欲しい情報を抜き出す技術になります。
具体的には、WebページはHTML言語をベースとしたプログラム言語によって表示されますが決まった規則に則って表示され私達が普段みるWebページが表示される仕組みとなっています。
例えば、株価の情報を提供する「株探」では、各会社ごとの株価の情報が表示されるわけですが、1社・2社ならページ遷移で確認すればすぐ見ることが出来るものの、100社見るとなったらどうでしょう。
1社例えば15秒ずつ見たとしても25分かかってしまいます。
そもそも100社分もいちいち検索してページ戻ってとかまた再検索してとか大変ですよね。
そこでこのWebスクレイピングという技術を使って自動でWebサイトのHTML情報を取得しみやすい形に整形してあげましょうというのが今回のお話になります。
※ちなみにWebスクレイピングを技術的に出来ないようにしていたり、利用規約で禁止していたりしますので実践してみようとするWebサイトの規約をよく確認した上で利用するようにしてください。
HTMLソースからデータを取得してみよう!
準備
1.HTMLデータをWebページから取得する
まずは、HTMLデータを取得するための準備を実施します。
Pythonを使ったHTMLデータの取得方法についてはこちらの記事を確認してみてください。
記事を取得できませんでした。記事IDをご確認ください。
2.HTMLデータを解析するモジュールを入れてみよう
次にHTMLデータを解析するためのモジュールを入れてみましょう。今回は”BeautifulSoup”を使ってみます。
前回の記事と同様に、[ターミナル]→[新しいターミナル]をクリックしてください。
3.BeautifulSoupをインストールしよう
BeautifulSoupのモジュールをインストールします。下のように入力し[Enter]ボタンを押してみましょう。
pip install beautifulsoup4
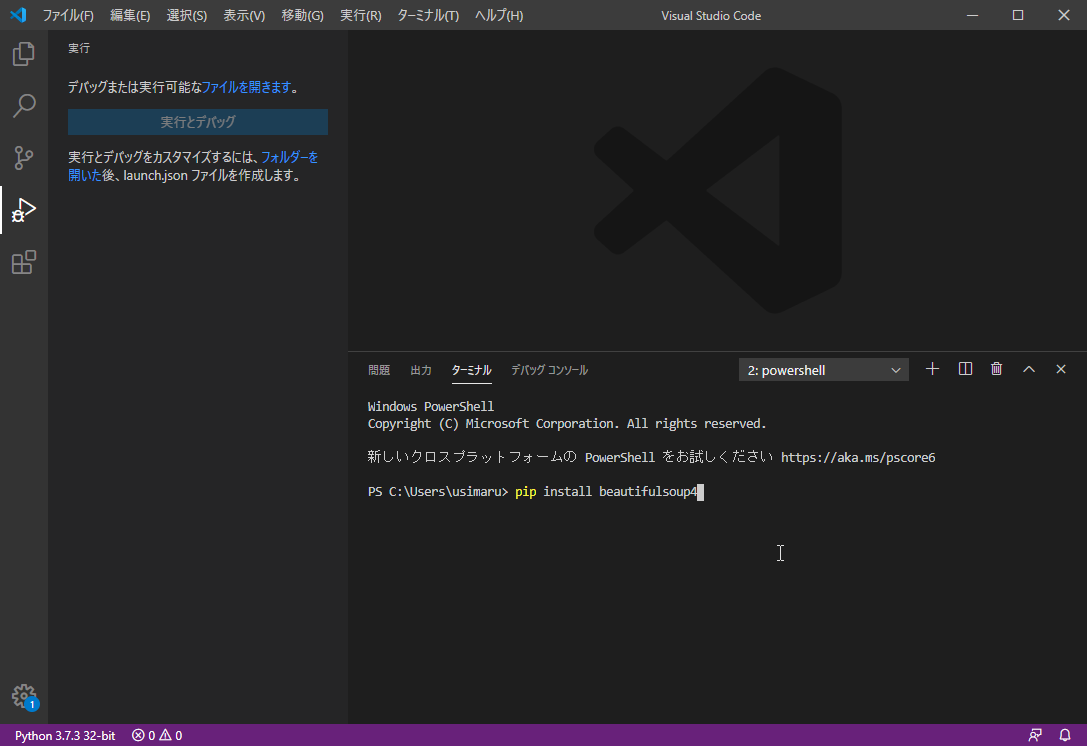
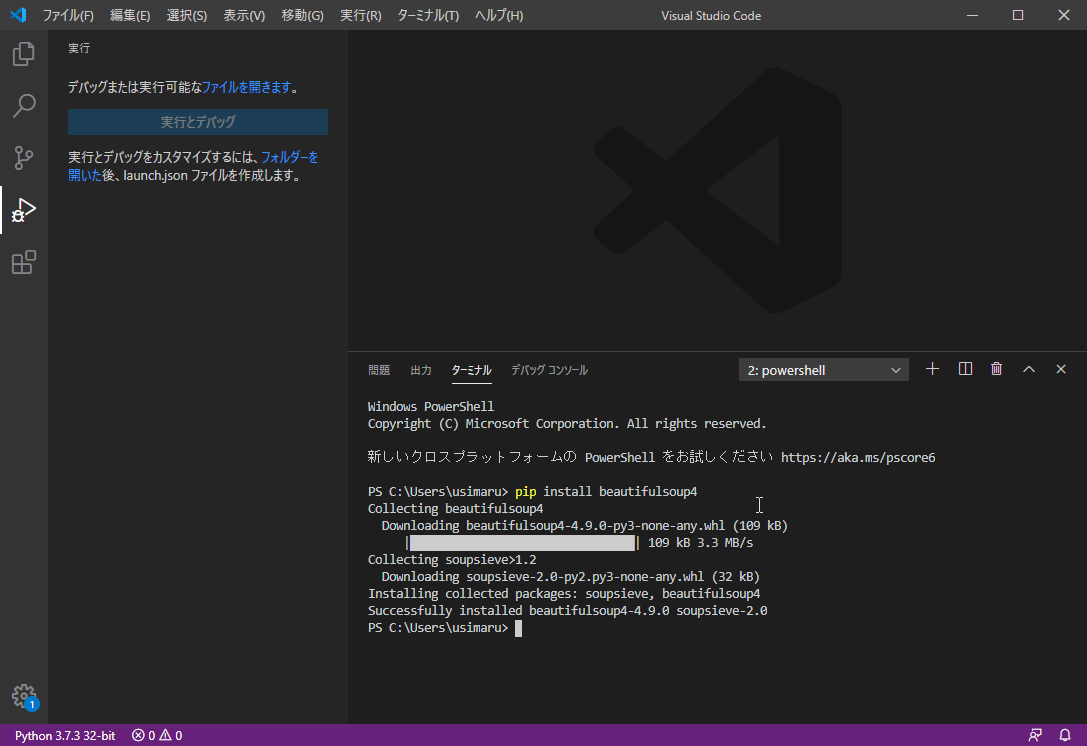
下のようになれば完了です。
4.lxmlを入れてみよう
こちらは必須では無いのですが、初めてBeautifulSoupを入れて何かしようという方は、必要となりますので入れてみましょう。BeautifulSoupでHTML文を解析するために必要なものとなります。
pip install lxml
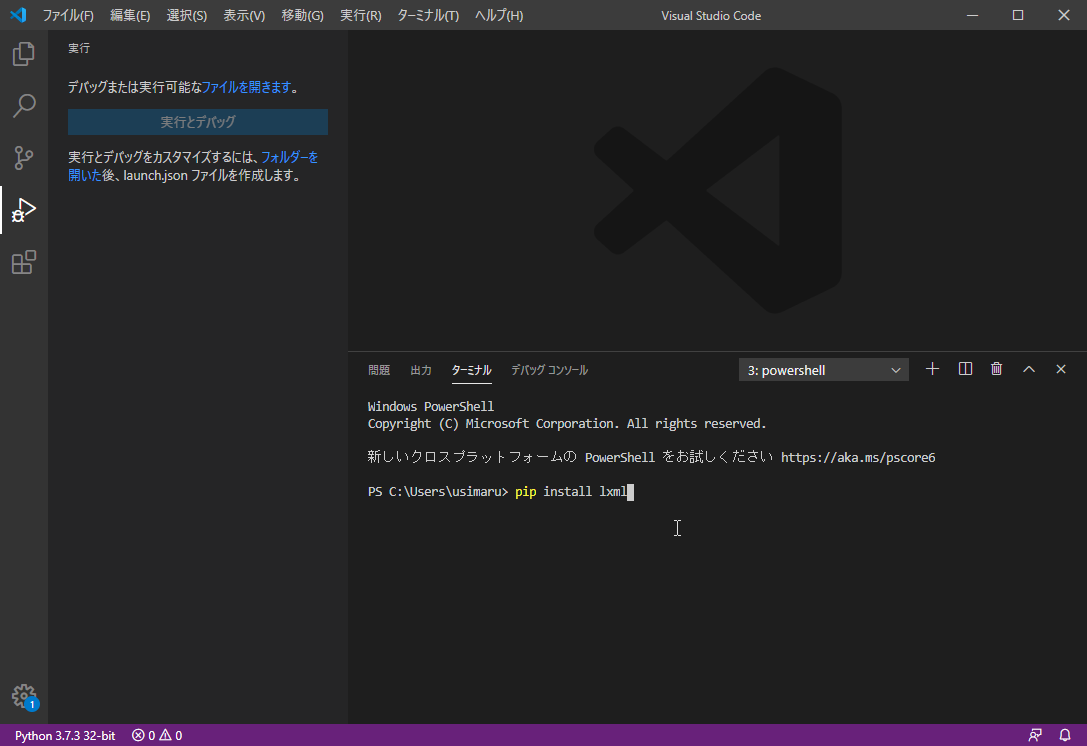
こちらも下のようになれば完了です。
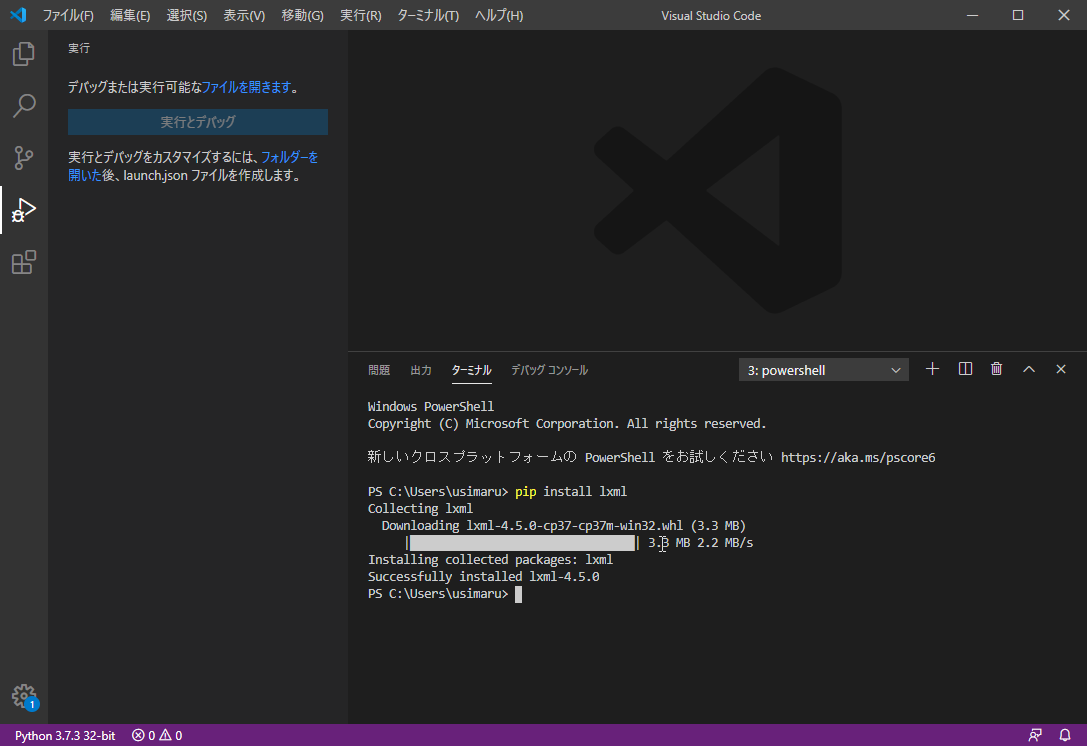
ここまでで事前準備は完了です。
動かしてみよう!
いよいよ、WebページからHTML情報を取得して、必要な情報を抜き出して見たいと思います。
まずは、コードを書いていきましょう。
#Requests/BeautifulSoupモジュールのインポート
import requests
import bs4
#読み込みたいWebページを指定
get_web_page = requests.get('https://kabutan.jp/stock/?code=2914')
#BeautifulSoup Objectへ格納
bsobj = bs4.BeautifulSoup(get_web_page.text, 'lxml')
#JT(2914)の株価を取得
print(bsobj.find('span', class_='kabuka').text)
まず、必要のモジュールをインポートしましょう。今回は“requests”と“bs4”をインポートしましょう。“requests”が関連記事で紹介しているWebページからHTML情報を取得するために使用するモジュール。“bs4”が今回の記事で準備したBeautifulSoupのモジュールとなります。
次に読み込みたいWebページを指定しましょう。”requests.get(’[URL]’)“でHTML取得情報を取得します。今回は株探より高配当銘柄の1つ、JTの銘柄ページより、株価情報を取得してみます。
ここからが今回の初の部分になります。詳しくてみましょう。
[変数] = bs4.BeautifulSoup([requestsオブジェクト].text, ‘lxml’)
“bs4.BeautifulSoup()”関数を実行することで[変数]へ、取得したHTMLの解析結果が格納されます。これでHTMLから好きな場所の情報が抜き出せるようになります。
では、具体的にどうやってHTMLソースを抽出すればよいのか確認していきましょう。
HTMLソースのどの位置に取得したいデータがあるのかを先に確認します。今回はChromeで見た場合の例を紹介します。
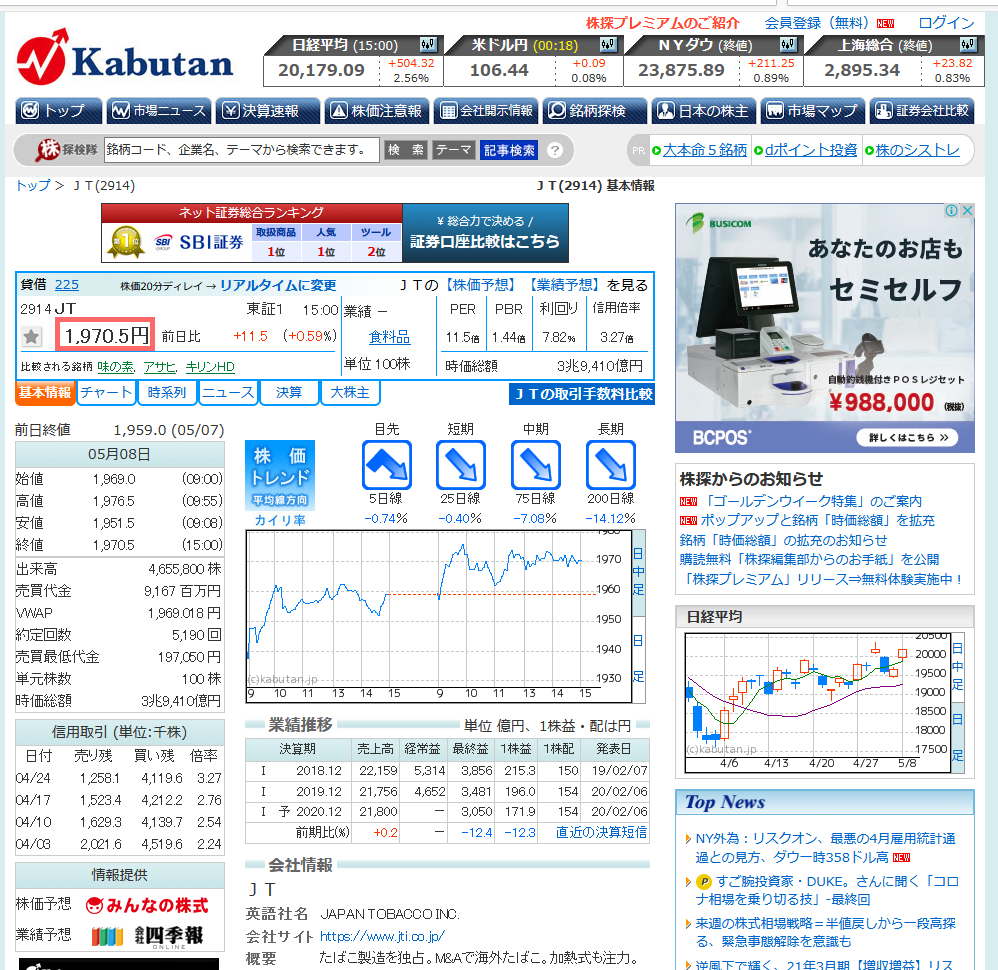
こちらは、先程取得する予定のページを実際にChromeで開いたときの表示結果です。今回は赤枠の部分を取得していきます。
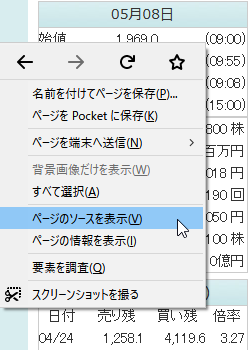
ブラウザ上で右クリックすると上の画像のようなコンテキストメニューが表示されますので[ページのソースを表示]をクリックしてみましょう。
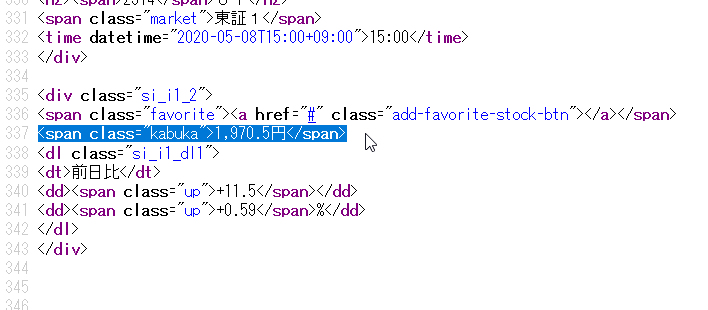
HTMLソースがずらーっと出てきますが特にHTMLの知識は必要ありません。価格が”1,970.5円”であることがわかっているのでCtrl+Fで出てくる検索ボックスにこの価格を入力して検索してみてください。無事見たかった場所が見つかります。ここで必要な情報は”<span class=”kabuka”>“となります。
では、ソースの解説に戻ります。
[BeautifulSoupオブジェクト].find(‘[タグ名]’, class_='[クラス名]’).text
HTMLソースそれぞれには意味があるので詳しくはHTMLの知識が必要ですが<>と</>の間に囲まれた部分は要素といって、必ずしもそうではないのですが、ページ上に表示される文字部分のことになります。
find関数を使うことでタグとクラスの情報からHTMLソース上の欲しい情報を取得することが出来ます。先程確認した”<span class=”kabuka”>“の場合、[タグ名]は”span”、[クラス名]は”kabuka”となりますので「find(‘span’, class_=’kabuka’)」と記載します。またこのままだと見つかった部分がすべて表示されてしまいますので要素だけを抽出するためにfind().textとしています。
では、実際に動かしてみましょう!
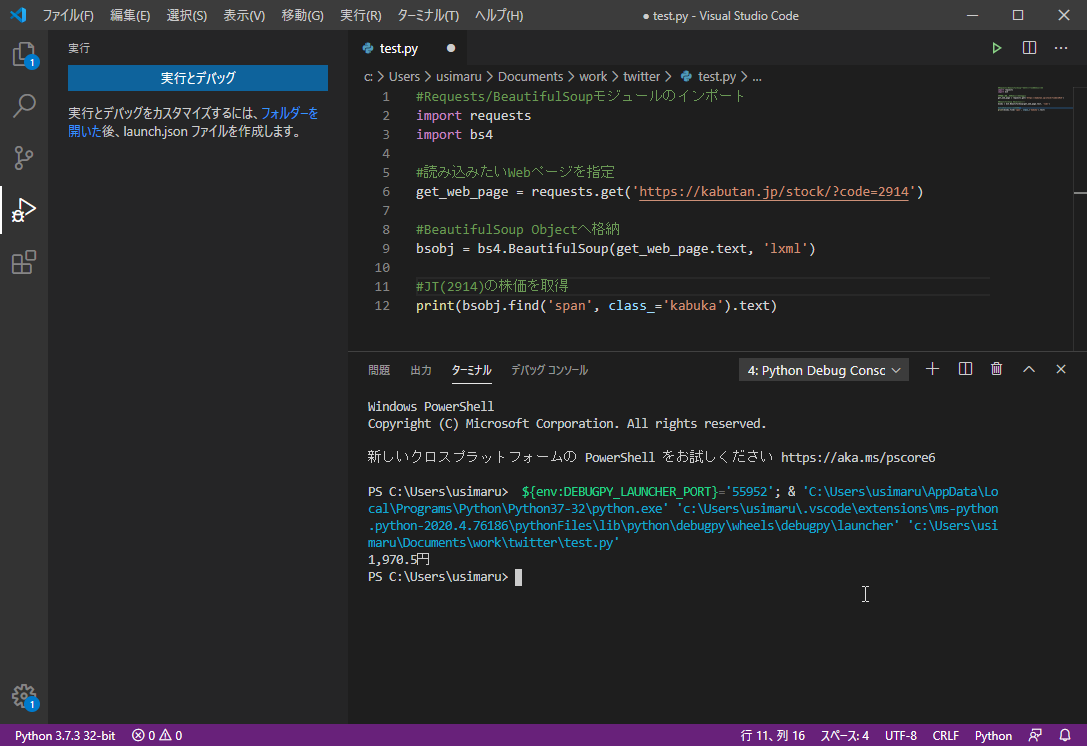
無事「1,970.5円」を取得することが出来ました。
まとめ
今回はPythonを使ってWebページのHTMLソースから情報を抜き出す方法について紹介しました。このやり方を覚えると様々なWepページから情報を自動で取得することが出来るようになりますので日々のデータ分析が少し楽になるのではないでしょうか。
それでは今回はここまでノシ
ポチッとしてもらえると励みになります!















コメントを残す
コメントを投稿するにはログインしてください。